

南湖新闻网讯(通讯员 肖仕杰)近日,我校工学院王巧华教授团队研究成果以“Rapid identification of A1 and A2 milk based on the combination of mid-infrared spectroscopy and chemometrics”为题在Food Control发表。研究揭示了A1和A2牛奶的光谱差异,建立了无损检测两种奶的分类模型,表明中红外光谱技术可作为无损快速鉴别A1奶和A2奶的新工具。该研究也可为单独组建A1型和A2型奶牛育种群提供相应的技术支持。
仅含A2β-酪蛋白的牛奶(A2奶)因其独特的健康益处而在全球广受欢迎。长期以来,企业需要先对奶牛进行专业的基因检测,筛选出β-酪蛋白中只包含A2β-酪蛋白的纯种A2奶牛,再用这些奶牛生产的牛乳加工成A2奶。基因检测虽准确性高,但成本也高且耗时长,无法满足乳企规模化生产的要求。因此,急需开发一种低成本、高效益的技术快速识别A1奶(普通奶)和A2奶。该研究突破了传统基因检测的局限,应用中红外光谱技术快速鉴别出A1和A2牛奶。
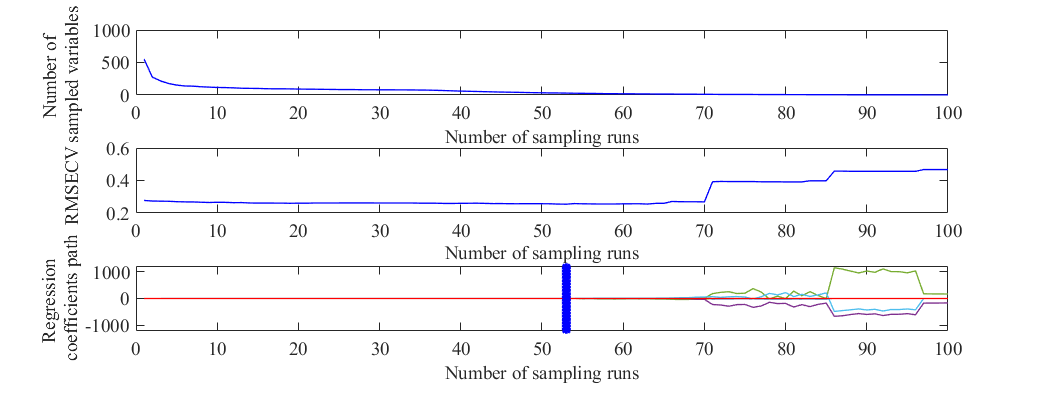
CARS算法筛选特征变量
该研究分析A1和A2牛奶在中红外光谱吸光度上的差异,找到敏感波段组合作为全光谱,分别利用标准正态变量变换 、多元散射校正、归一化、一阶导数、二阶导数、一阶差分和二阶差分等7种方法对光谱进行预处理,利用无信息变量消除法和竞争性自适应重加权算法筛选出能代表A1和A2奶差异的特征变量,进而构建偏最小二乘判别分析(PLS-DA)模型和支持向量机(SVM)模型,PLS-DA模型的训练集准确率和测试集准确率分别为96.6%和96.0%,SVM模型的训练集准确率和测试集准确率分别为96.0%和95.1%。
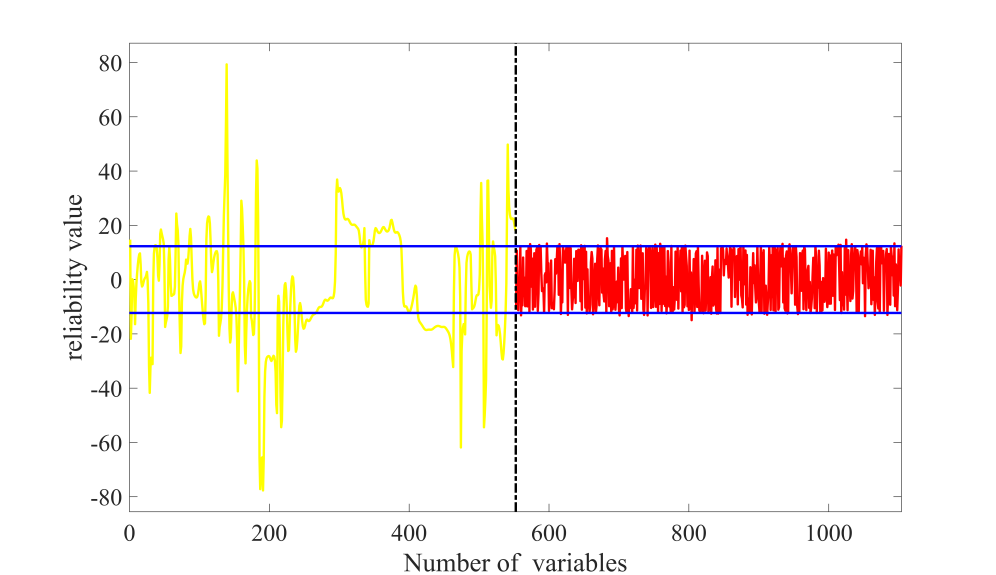
UVE算法筛选特征变量
该研究选择PLS-DA模型作为最佳模型,使用一组独立样本对模型进行外部验证。将新采集的牛奶中红外光谱批量带入保存的模型中,以对应的奶牛基因检测结果作为对照指标,模型的预测准确率为95.2%,性能良好。结果表明,中红外光谱技术可以实现对A1奶与A2奶的快速分类鉴别,有望将来在生产中得到应用。
华中农业大学工学院硕士研究生肖仕杰为论文第一作者,工学院王巧华教授和动物科学技术学院张淑君教授为共同通讯作者。该研究得到中国政府项目(2013070204020045)资助。
审核人:王巧华
【英文摘要】
The milk containing only A2 β-casein (called A2 milk) is globally popular because of its unique health benefits. Traditionally, genetic testing (such as gene sequencing) is used to identify the cows with A2 β-casein gene that can only produce A2 milk, which is a time-consuming and costly method. The objective of this study was to directly identify A1 and A2 milk from a large quantity of milk using mid-infrared (MIR) spectroscopy and chemometrics without genotyping cows. Before establishing the predictive model, we firstly genotyped the A1 β-casein and A2 β-casein of cows from blood as reference values. Further, the MIR spectra of the milk collected from these cows were obtained using a dairy product analyzer. The MIR spectroscopy data and the reference values were used as the independent and dependent variables, respectively, to establish a category classification model for A1 and A2 milk. Seven preprocessing methods were combined with two feature extraction algorithms to establish the model. Subsequently, partial least squares discriminant analysis (PLS-DA) and support vector machine (SVM) models were developed. The average accuracy of the test set of the two models were 94.9% and 94.4%, respectively, while the PLS-DA model exhibited better effect, and the accuracy of training set and test set reached 96.6% and 96.0%, respectively. We used a set of independent samples for the external validation of the PLS-DA model, and the prediction accuracy was 95.2%. Overall, the proposed prediction models based on MIR spectroscopy can be used for low-cost, rapid, and large-scale classification of A1 and A2 milk, which may be extremely beneficial in milk production industries.